📝 Postmortem Report – NGINX Upstream DNS Resolution Failure
1. Summary
- Incident ID/Name:
NGINX-Upstream-DNS-20250924 - Date & Time: 2025-09-24, 10:12 – 10:30 IRST
- Duration: \~18 minutes
- Severity Level: SEV1 (Critical)
- Systems Affected: NGINX upstream services (
srv190), DNS resolution layer - Impact on Users/Business: 100% outage. All panels and web services returned 502 Bad Gateway errors. Users could not access the platform during the incident.
2. Incident Timeline (IRST)
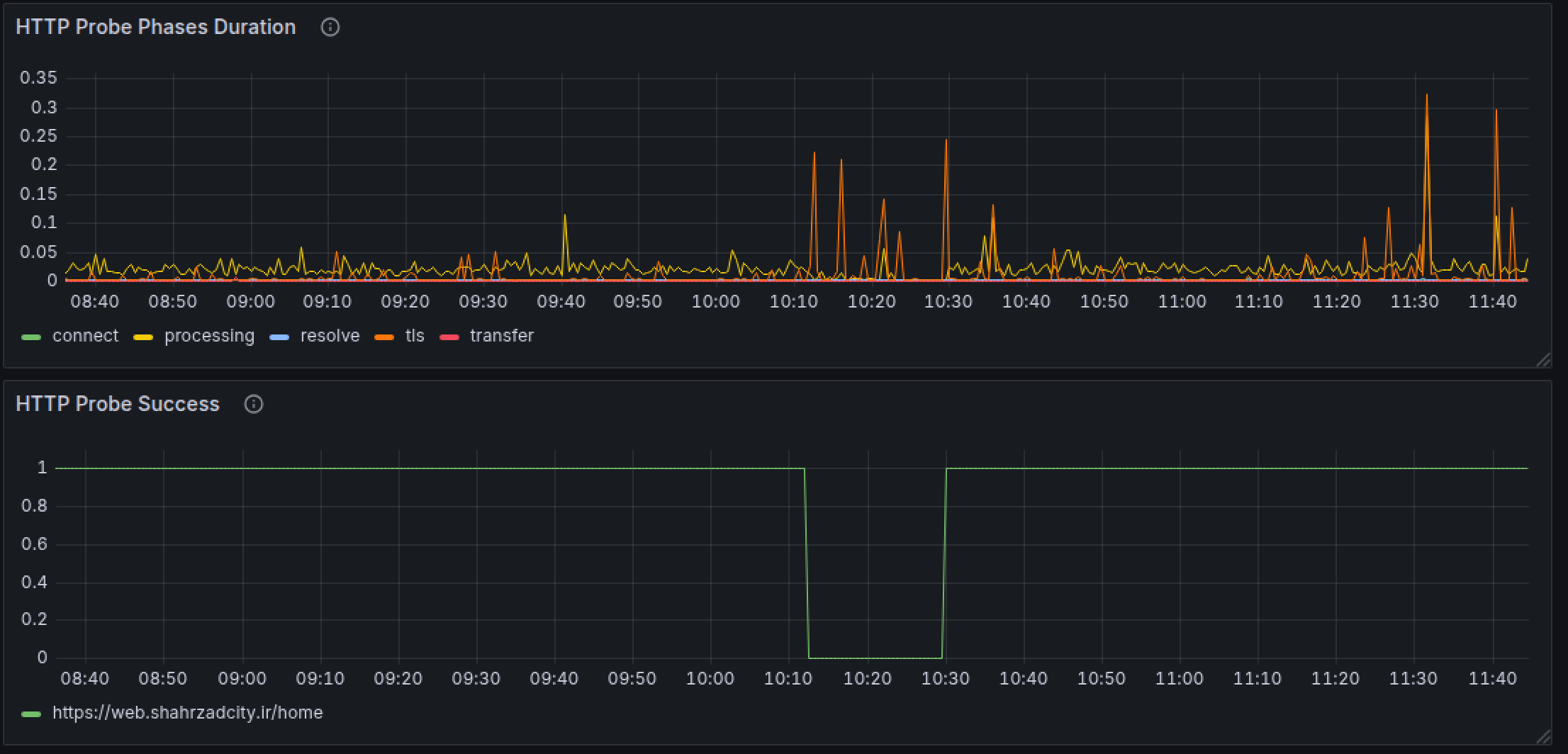
- 10:12 – DNS resolution failures began for upstream defined in NGINX.
- 10:13 – Panels and web services returned 502 errors.
- 10:15 – Alerts fired, on-call engineer acknowledged incident.
- 10:18 – Suspected DNS resolution issue from FAVA side.
- 10:22 – Confirmed upstream had only
srv190and configured resolver (FAVA) failed to resolve. - 10:26 – Engineers added alternative resolvers + three backup upstream servers.
- 10:30 – NGINX restarted successfully, all services restored.
3. Root Cause Analysis
-
Immediate Cause: NGINX runtime error due to DNS resolution failure → caused process stop and 502 responses.
-
Underlying Causes:
-
Only a single upstream server (
srv190) defined. - Resolver was configured, but FAVA DNS resolvers failed, preventing proper resolution.
-
Lack of redundancy and failover handling for upstreams.
-
Why It Wasn’t Prevented/Detected Earlier:
-
Monitoring didn’t cover DNS resolution failures.
- No resilience or chaos testing for DNS outages.
4. Impact
- User Impact: 100% of requests failed (\~18 minutes full downtime).
- Internal Impact: High urgency; on-call engineers required immediate troubleshooting.
- Customer Communication: Internal-only escalation; no external comms sent (platform fully down but recovered quickly).
5. Resolution & Recovery
-
Actions Taken:
-
Added alternative DNS resolvers and three backup upstream servers.
-
Restarted NGINX to restore traffic.
-
Key Metrics:
-
TTD (Time to Detection): \~3 minutes
- TTM (Time to Mitigation): \~14 minutes
- TTR (Time to Recovery): 18 minutes total
6. What Went Well ✅
- Alerts fired promptly.
- Root cause (DNS resolution failure) identified quickly.
- Fix (alternative resolvers + upstream redundancy) applied effectively.
- Service restored fully within 20 minutes.
7. What Went Wrong ❌
- Single upstream created a fragile single point of failure.
- Resolver was configured, but FAVA DNS resolvers failed, causing NGINX crash instead of graceful fallback.
- No upstream redundancy.
- Monitoring blind spot: DNS issues went undetected until total outage.
8. Action Items 📌
- [x] Ensure minimum 3 upstreams per service (Owner: DevOps, Due: Sept 30)
- [x] Add alternative DNS resolvers in NGINX configs (Owner: DevOps, Due: Sept 28)
- [ ] Add DNS resolution + upstream health monitoring (Owner: SRE, Due: Oct 5)
9. Lessons Learned 💡
- DNS must be treated as a critical dependency.
- Single upstream setups create unacceptable fragility.
- Resolver configuration alone is insufficient — multiple resolvers or fallback mechanisms are necessary.
- Chaos/resilience testing is essential to validate platform stability under external dependency failures.
10. References 📂
- BlackBox monitoring dashboards
- Notes and data from Ali Peyman (DevOps Lead)